
Every penetration tester has had the moment. You are two days into an engagement, sifting through cloned repositories and intercepted HTTP responses, and a hardcoded AWS key appears in a config file that has been sitting in version control for months. Nobody rotated it. Nobody noticed. And when you validate it, the key is still live.
Leaked secrets are not a new problem. The tooling for finding them has improved dramatically over the past several years, with mature open-source rule sets covering hundreds of credential patterns across cloud providers, SaaS platforms, CI/CD systems, and payment processors. But most of this tooling operates in exactly one context: you point a CLI scanner at a directory and read the output. That is the blind spot.
The Problem Is Not Detection Rules
During a typical offensive engagement, credentials surface across multiple attack surfaces at once. Source code repositories are the obvious ones, but secrets also appear in HTTP responses intercepted through a proxy, in JavaScript rendered by the browser, in exported spreadsheets and PDF reports, inside mobile application packages, and embedded in database dumps. A scanner that only runs against a local filesystem misses everything else.
The detection engine needs to exist in more than one place. Consider what changes if the same rule set runs passively inside an intercepting proxy, scanning every HTTP response as it flows through your testing workflow. Secrets that appear in API responses, JavaScript bundles, and dynamically rendered pages get flagged without any extra effort on your part. Or consider embedding the same engine as a browser extension that scans page content in real time, catching credentials that only exist in client-side code after JavaScript execution.
The point is not that any single integration is revolutionary. It is that running the same detection logic across CLI, proxy, and browser contexts simultaneously closes gaps that exist when each surface is treated as a separate problem.
Validation Is The Real Force Multiplier
Anyone who has run a regex-based secret scanner on a large codebase knows the false positive problem. Test fixtures, placeholder values, example configurations, and documentation samples all trigger rules. On a big engagement, you can end up with hundreds of hits that require manual triage before you know which ones matter.
Automated validation changes the equation entirely. For each detected credential, a controlled API call can determine whether it is live. A 200 response confirms the key works. A 401 or 403 means it has been revoked. An unreachable endpoint gets flagged as unknown. When this runs concurrently against every finding, what used to be a manual sorting exercise becomes an automated prioritization step.
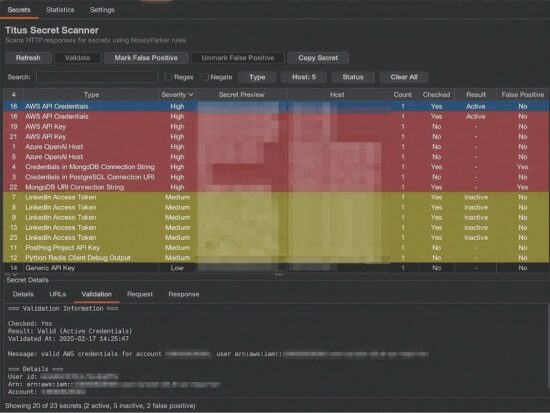
The implementation is straightforward. Each detection rule optionally defines a validator: a templated HTTP request that specifies how to test the credential and how to interpret the response. This is not novel computer science. It is plumbing. But it is plumbing that eliminates hours of manual work per engagement.
Do Not Ignore Binary Files
Most secret scanners only examine plaintext, but credentials routinely live in places that require extraction first. Exported spreadsheets, PDF reports, Jupyter notebooks, SQLite databases, and mobile application packages all regularly contain hardcoded API keys and service tokens. Archive formats compound the problem further. A zip inside a zip, a JAR inside a WAR, or an IPA containing embedded configuration plists all require recursive extraction before any scanning can happen. If your detection strategy skips binary formats, you are leaving real findings on the table.
LLMs as a Second Pass
Validation catches some false positives, but not all. A test key will not return a 200 from a cloud provider, yet it still clutters your results. Large language models offer a practical denoising layer. Feeding each finding and its surrounding context into an LLM and asking whether the match looks like a real credential or a false positive eliminates a meaningful chunk of remaining noise. Three years ago, this would have been impractical. Today it is a fraction of a cent per finding and adds negligible time to the overall workflow.
From Detection to Lateral Movement
Finding a credential is step one. The natural next move is testing it at scale across the target environment: SSH, RDP, SMB, database protocols, and anything else listening on the network. A single leaked password that works against three internal services is no longer just a secret exposure finding. It is a lateral movement map. The workflow from detection to validation to credential spraying is a kill chain that offensive teams are increasingly automating end-to-end.
What This Means for Defenders
The tooling available to attackers for finding, validating, and exploiting leaked credentials is becoming increasingly integrated and automated every quarter. If you are on the defensive side, auditing source code repositories alone is not enough. You need to look at binary artifacts, exported documents, CI/CD pipeline outputs, and browser accessible internal applications. Automated secret rotation, short-lived tokens, and vault-based credential management remain the best countermeasures. When an attacker finds a credential in your environment, the answer to whether it still works should already be no.

Michael Weber is an Offensive Security Developer at Praetorian with over a decade of experience in malware reverse engineering, penetration testing, and security tool development.

Noah Tutt is a Senior Security Engineer at Praetorian specializing in web application assessments, hardware testing, reverse engineering, and secure code review.

Zach Grace is a Principal Security Engineer at Praetorian with extensive consulting experience across cloud, application security, red teaming, social engineering, and physical penetration testing.
The opinions expressed in this post belong to the individual contributors and do not necessarily reflect the views of Information Security Buzz.