
Today’s static groups are an essential building block in most policies used to “authorize” access to application resources. So when we talk about providing finer-grained authorization for an existing application, we are essentially talking about finding a better way to dispatch users to the different existing roles. Now, these roles are mostly associated with an application’s resources, which are pretty stable—except when the application allows a user to create new “resources,” such as report pages, that can be shared and hence could need authorization.
Because roles and application resources are created at application design-time, they’re only updated when there are product upgrades and new releases. So unless you’re facing a complete new release of an application with major new features (and hence new resources), the finer-grained mechanism for authorization—the real degree of freedom that exists for users of an application—resides in your ability to dispatch people to different groups and to switch those groups between different roles as the business demands.
Give Me Granularity or Give Me Death: The Evolution of RBAC
We know that more granularity at the level of authorization translates directly into more flexibility at the level of business. With greater granularity, you’re free to dispatch people into roles and groups according to your business requirements—and ideally, you don’t have to lean on the IT team as much. But here’s where the notion of “static” groups starts to become a hindrance for better business agility within the security realm. In fact, the whole progressive evolution toward Attribute-Based Access Control began with groups based around a static association of “labels” with respective populations, such as “Sales,” “Marketing,” “Production,” “Gold” and “Silver” customers, and the like:
Step 1: RBAC Based on Static Groups
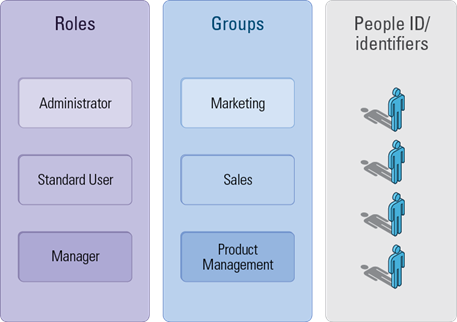
But usage quickly dictated the introduction of a finer-grained way to characterize these populations. Hence, the introduction of subgroups:
Step 2: RBAC with Sub/Nested Groups
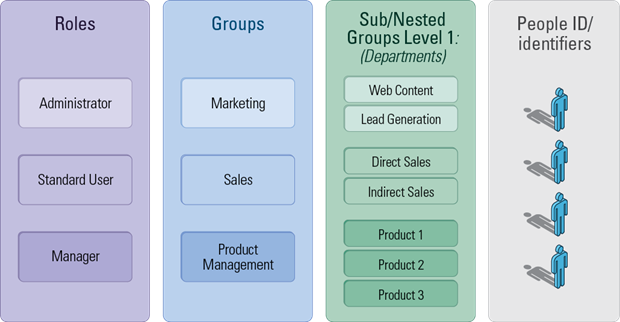
Notice that the introduction of one level of sub-grouping is equivalent to adding a second column of labels that now subdivide each group. If we go a few iterations further, we see the introduction of multi-level grouping, for a full hierarchy of groups:
Step 3: RBAC with Sub-Groups of Many Levels
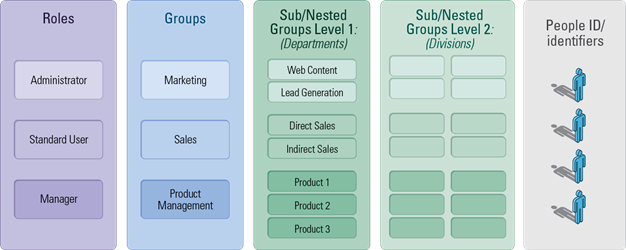
Implicitly, even if those levels are not named, you can think about each of them as a sublevel of the group hierarchy (sublevel 1, sublevel 2, etc…). But as this hierarchy starts to grow, we quickly discover the management challenge this poses. Sure, you get a finer-grained way to dispatch your users, but you have to satisfy two constraints:
1) You need to define a vocabulary that’s consistent across the entire organization—and if this set of labels is not enforced across the org chart, you’ll not only have a data quality issue, you won’t be able to give the right person access to the right resource. So if one set of people in your organization creates a group called “Product Marketing” and another “Product Management,” you need to know whether these are two completely separate groups, two groups with some overlap, and or if they have any dependencies, where one group is a subgroup of another.
2) Once the group labels are created, you still need to assign/administrate those people to these different groups. And, alas, the information about who belongs to which group is only in the mind of the administrator, which means these assignments are done manually, and not by any data-driven rule. So it’s labor-intensive and potentially a bottleneck in an otherwise automated authorization chain.
Flexibility = Agility: The Emergence of Attributes and ABAC
I’m sure you noticed that when we moved from step 2 to step 3, we began to introduce a title for each level of subgroups. And of course, here we are cheating with the benefit of hindsight. As you try to normalize the vocabulary or criteria of grouping for each sublevel, you will discover that if you want consistency in terms of classification/categorization, you’d better use a homogeneous common characterization for every level (unless you want to induce chaos by starting to mix apple and oranges).
So level 1 could be a subgrouping based on department, locality, or some other factor. As you start to explicitly name these categories of grouping for each level, you are discovering that the hierarchy is nothing more than a finer-grained characterization of your demographics per attribute. In this way, groups and nested subgroups act as a poor man’s version of attribute-based segmentation.
Step 4: Finally ABAC, Where Every Column Can Be Seen as an Attribute
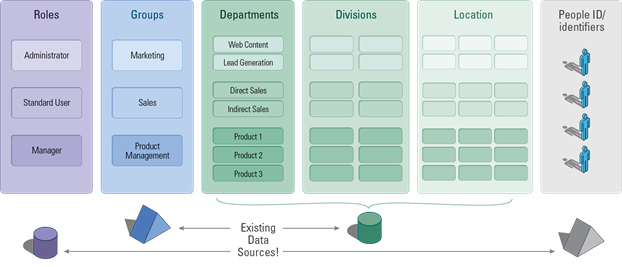
So even though ABAC has long seemed out of reach, a better understanding of the groups and group nesting we use for RBAC drives us much closer to the introduction of attribute-based grouping. Now if only we could find a way to automate the process…hmm, should we reinvent all those categorizations and their labels to enable ABAC? No—if each user could be characterized in his or her own record by those attributes, we can kill two birds with one stone: the attributes (columns) and their values would be the base for automatically dispatching the user to the relevant group. Assignment to groups would then be data-driven instead of an unending manual process.
Now where would such attributes show up? Yes, you guessed it—most of the time they have already been captured in your current applications and data silos. The trick is how we can associate these scattered attributes with an end user. If you’d like to see this in action, you can check out, “ABAC to the Future: Deliver Smarter SiteMinder Policies with No Sweat.”
Michel Prompt, Founder and CEO, Radiant Logic
 Michel is a world-renowned developer, researcher, and entrepreneur. Prior to founding Radiant Logic in 1995, Prompt served as Senior Vice President of Client/Server Technology at Knowledgeware, now known as Sterling Software. In 1986, Prompt founded Matesys SA in France, a company dedicated to providing services and database support. Matesys introduced the first “file-manager,” duplicating the “Apple Macintosh finder” under Windows 2.1 and sold 500,000 copies to IBM for academic bundles. Prompt founded Matesys Corp., in the U.S., in 1991, becoming one of the pioneer companies in client/server technology. Matesys introduced one of the first visual programming tools under Windows 3.0 for the client/server market (Object View). Prompt successfully sold the company to Knowledgeware in 1993.
Michel is a world-renowned developer, researcher, and entrepreneur. Prior to founding Radiant Logic in 1995, Prompt served as Senior Vice President of Client/Server Technology at Knowledgeware, now known as Sterling Software. In 1986, Prompt founded Matesys SA in France, a company dedicated to providing services and database support. Matesys introduced the first “file-manager,” duplicating the “Apple Macintosh finder” under Windows 2.1 and sold 500,000 copies to IBM for academic bundles. Prompt founded Matesys Corp., in the U.S., in 1991, becoming one of the pioneer companies in client/server technology. Matesys introduced one of the first visual programming tools under Windows 3.0 for the client/server market (Object View). Prompt successfully sold the company to Knowledgeware in 1993.
Prior to Matesys, Prompt was a core developer in the database group of the GCOS 7.0 Operating System for Bull Systems. He also served as a consultant to Cap Sogeti Gemini, one of the largest IT service companies in Europe. Prompt received his diploma from Institut Politiques de Paris (Political Sciences Institute of Paris). He holds a Masters degree in applied mathematics from Paris Dauphine University and received a diploma of advanced studies in computer science from Paris Dauphine University.
The opinions expressed in this post belong to the individual contributors and do not necessarily reflect the views of Information Security Buzz.